Как моделировать системы управления¶
Логика моделирования¶
Каждая модель реализуется в виде отдельной задачи на Python — она запускается в отдельном процессе и содержит как уравнения и алгоритмы модели, так и методы численного расчёта этих алгоритмов. Задача должна произвести расчёт своих выходных величин на некоторый интервал времени. Подобно тому, как это реализовано в SimInTech, задача имеет несколько состояний (см. рис.), переход между которыми происходит по командам диспетчера, либо по внутренним событиям задачи.
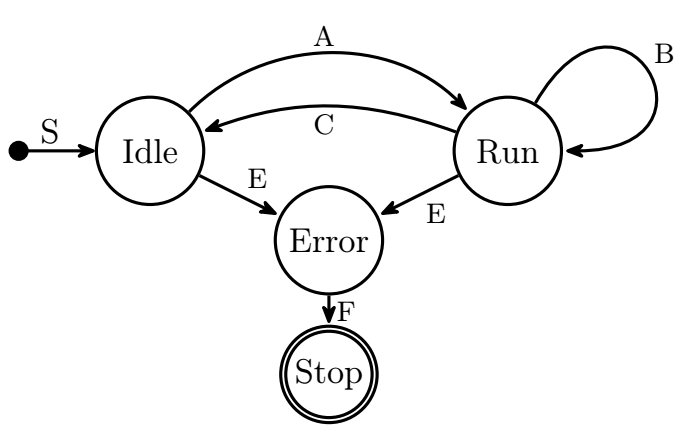
После получения команды на старт моделирования задача переходит (A) из состояния ожидания Idle в состояние работы Run; при этом происходит инициализация графики и внутренних переменных задачи (выставляется начальное состояние). После этого диспетчер циклически выдаёт каждой задаче команду на произведение расчётного шага (B), передавая при этом задаче исходные данные (результат расчёта смежных с ней задач), и забирая результаты расчёта (чтобы передать их последующим задачам). По окончанию расчётного времени задача переходит в состояние ожидания (C), выполняя действия для финализации расчёта (дорисовка графики, закрытие файлов). Если во время расчёта происходит внутренняя ошибка, задача переходит в состояние ошибки (E) с выдачей сообщения об ошибке диспетчеру, а затем останавливается; при этом по команде диспетчера остальные задачи переходят в состояние ожидания.
Обмен данными производится с использованием UDP-пакетов, которые содержат требующиеся для конкретной задачи переменные из общей базы данных. Каждая задача содержит менеджер базы данных; он производит распаковку/запаковку пакетов и раскладывает данные по внутренним переменным класса задачи. Подобная система реализована в статье [3], где обмен производится с оборудованием стенда, работающим подобно задаче.
База данных¶
База данных должна содержать собственно базу переменных, которые будут общими между задачами. Также она содержит список задач с указанием, какие переменные нужно передавать и принимать от задачи (какие передаются, такие и принимаются).
После инициализации (см. метод __init__ шаблона задачи) в атрибутах класса появится объект Manager, который является менеджером базы данных. Именно он создаст (при своей инициализации) в объекте задачи атрибуты, которые являются полями общей базы данных - они будут синхронизироваться каждый расчётный шаг задачи.
Менеджер создаст только требуемые для конкретной задачи поля базы данных, взяв их из словаря Tasks.
Общая база данных, её поля, состав конкретных переменных для обмена с конкретными задачами задаются в классе-контейнере, в виде атрибутов:
class DataBase():
# --- общие переменные ---
t = 0. # время
dt = 0.25 # шаг задач
tmax = 4. # время моделирования
cmd = 0 # команда всем задачам
# --- пользовательские переменные ---
U = np.array([0.1, 0., 0.]) # управление
L_B = np.zeros(3) # магнитное поле катушек
B_I = np.array([0., 1e-5, 0.]) # магнитное поле (I), [T]
B_B = np.zeros(3) # магнитное поле (B), [T]
Mm_B = np.zeros(3) # вращательный момент от катушек
Ma_B = np.zeros(3) # вращательный момент от аэродинамики
M_B = np.zeros(3) # вращательный момент суммарный
# dw_B = np.zeros(3) # угловая скорость - производная
w_B = np.zeros(3) # угловая скорость
# dq_IB = quat.Quaternion(), # производная кватерниона
q_IB = quat.Quaternion() # кватернион связанной СК относительно инерциальной
q_IO = quat.Quaternion() # кватернион орбитальной СК относительно инерциальной
В текущей версии можно использовать следующие типы:
int,
float,
numpy.ndarray (для векторов),
Quaternion (для кватернионов).
Дополнить типы можно в коде менеджера, в файле libKernel.py
База и список задач (см. далее) должны быть записаны в отдельном файле (обычно db.py), который нужно импортировать в каждой задаче (чтобы в одном месте назначить переменные задачам). Для одиночных задач БД можно определить прямо в файле задачи (см. пример ex.1), только нужно не забыть указать её в параметрах задачи.
Варианты синтаксиса¶
Здесь есть нюанс, связанный с особенностями синтаксиса языка.
В рассмотренном выше варианте описания класса переменные определены вот так:
class DataBase():
t = 0. # время
Переменная t, определённая вне метода (например __init__), является переменной класса. Она принадлежит самому классу и доступна для всех экземпляров этого класса.
А можно определить класс вот так:
class DataBase():
def __init__(self):
self.t = 0. # время
Здесь переменная t, определённая внутри метода __init__, является атрибутом. Она создаётся отдельно для каждого конкретного экземпляра класса.
Отличия - в области видимости.
Переменная класса: Доступна сразу же при создании самого класса и является общей для всех объектов этого класса. Изменение её значения влияет на все объекты одновременно. Если переменную нужно изменить глобально для всех объектов, используется переменная класса.
Атрибут экземпляра: Создаётся отдельно для каждого объекта при инициализации экземпляра (через метод __init__) и изменения в одном объекте не влияют на остальные. Если каждому объекту нужен собственный уникальный экземпляр атрибута, лучше использовать атрибут экземпляра.
Резюме:
Переменая класса |
Атрибут класса |
|
|---|---|---|
Объявляется |
Прямо в классе |
Внутри метода |
Принадлежит |
Классу |
Экземпляру |
Изменяется |
Для всех объектов |
Только для текущего объекта |
Использовать |
Когда значение общее |
Когда нужны индивидуальные |
Допустим, нужно запустить оптимизацию переходного процесса, варьируя параметры системы.
Обычно делается так - пишем целевую функцию для минимизации. Внутри нее рассчитывается переходной процесс, для которого вычисляется метрика, например какая-либо интегральная оценка качества переходного процесса, в простейшем случае сумма квадратов сигнала ошибки. Потом отправим эту функцию на минимизацию.
На входе в целевую функцию передаются оптимизируемые параметры. Удобно сделать их переменными базы данных - задал и вызвал расчет переходного. Но, если все переменные, включая переменные состояния модели, будут заданы как переменные класса, то при повторном запуске их значения сохранятся с предыдущей итерации (т.е. расчет как бы продолжится). Даже если мы заново создадим новый экземпляр класса базы данных - переменные сохранят значение.
Поэтому, для таких случаев нужно определять переменные состояния как атрибуты класса.
Список задач¶
Задачи вызываются в порядке следования в словаре Tasks
Tasks = {
'Rotation':{'Keys':"""t,cmd,dt,
U,L_B,
B_I,B_B,
Mm_B,Ma_B,M_B,
w_B, q_IB"""},
'Control':{'Keys':['t','cmd','g','u','x1']},
'Plot2D': {'Keys':'t,cmd,dt,q_IB,sinx'},
}
Здесь задано три задачи (Rotation, Сontrol и Plot2D), имена которых являются ключами в этом словаре задач.
Имя задаче присваивается автоматически, оно соответствует имени класса задачи. Т.е. когда вы создаёте экземпляр класса, например так
model = Control(TaskList=libKernel.prepare(db.Tasks), DB=db.DataBase(), isSheduler=True)
то эта задача получит имя Control и её менеджер будет искать это имя в списке задач, чтобы понять - какими переменными нужно обмениваться с БД. Понятно, что имя задачи не обязательно должно совпадать с именем py-файла, содержащего задачу.
Ключи имеют значение тоже типа словарь (dict), в котором есть обязательный ключ Keys. В нём указаны поля базы данных, которыми будет осуществляться обмен с данной задачей. Только они будут запаковываться в udp-пакет, который отправится по указанному адресу на задачу. По типу данных это может быть список из строк (имена полей), строка (имена полей через запятую) или многострочная строка (тоже имена полей через запятую).
Если обмен данными производится с удалённой системой, то необходимо задать сетевой адрес, по которому будут отправляться пакеты с данными. В этом случае добавляется ключ Addr, значение которого должно быть кортежем и иметь вид (ip-адрес, порт), например
Tasks = {'Rotation':{'Keys':"t,cmd,dt",
'Addr':('172.12.89.121', 6523)
}
Сам диспетчер работает на порту 7800 (поменять можно в libKernel). Этот адрес на локальной машине занимать нельзя.
Иногда от некоторые задачи могут и не возвращать данные, а только принимать их. Это обычно графика - маотбработка и отрисовка двумерных и трёхмерных графиков. Они обычно занимают значительное время цикла.
Чтобы разгрузить диспетчер, чтобы не ждать ответа от них, можно использовать специальный флаг noAnswer. Он добавляется как ключ в словаре задач:
Tasks = {'Plot2D': {'Keys':'t,cmd,dt,u,w,m,m2',
'Addr':('188.162.92.109', 6502)},
'noAnswer':True
}
Вынос графики в отдельную задачу значительно уменьшает фактическое реальное время шага.
Как писать задачи¶
Код задачи выглядит как описание класса на Python, который должен иметь методы с определёнными именами, которые вызываются при переходах между состояниями; в них требуется задать расчётный код модели. Машина состояний и менеджер базы данных реализованы в родительском классе, от которого нужно унаследовать класс с описанием задачи.
Вот код родительского класса:
class TaskTemplate():
""" шаблон для задач
Каждая задача должна быть оформлена как класс, наследоваться от TaskTemplate
и иметь методы Setup, Run, Initialize, Finalize
Args:
TaskList (list): список задач, в котором указаны переменные БД для обмена и некот. параметры
DB (kernel.DataBase): объект бд общей (в kernel.py)
isSheduler (bool): содержит ли задача диспетчер (запускает ли другие). Такая должна быть одна, и запускаться последней
isRealTime (bool): работаем в реальном времени (атрибут t соответствует реальному времени)
"""
def __init__(self, TaskList=None, DB=None, isSheduler=False, isRealTime=False):
self.name = type(self).__name__ # имя класса, по нему поиск в таблице задач TaskList
self.Manager = DBaseManager(task=self, TaskList=prepare(TaskList),
DB=DB, isSheduler=isSheduler, isRealTime=isRealTime)
self.Setup()
def Setup(self):
""" запускается один раз, при создании задачи """
pass
def Initialize(self):
""" запускается при инициализации задачи, перед запуском (Run) """
pass
def Run(self):
""" запускается циклично, для каждого интервала времени dt """
pass
def Finalize(self):
""" запускается при завершении задачи, после Run """
pass
По коду понятно, что нужно переопределить (при необходимости) методы Setup, Initialize, Run и Finalize, задав в них требуемую модельную логику.
Методы выполняются на следующих переходах машины состояний:
S Setup
A Initialize
B Run
C Finalize
На переходах в состояние ошибки (Error) и в останов (Stop) выполняются внутренние служебные методы задачи, в которые пользователю не следует вносить логику задачи (код доступен в libKernel.py).
Примеры кода задач приведены в разделе Примеры.
В конце файла с задачей нужно создать экземпляр класса и передать управление машине состояний задачи:
model = Controller(TaskList=libKernel.prepare(db.Tasks), DB=db.DataBase(), isSheduler=False, isRealTime=False)
model.Manager.Loop()
Параметрами класса задачи указываются:
TaskList: список задач Tasks. В текущей версии он должен быть подготовлен функцией prepare библиотеки libKernel.
DB: объект общей БД
isSheduler: флаг, показывающий содержит ли задача диспетчер и запускает ли другие задачи. Одна из задач должна запускать все остальные и обеспечивать обмен данными. Такая должна быть одна, иметь флаг isSheduler=True и запускаться последней. Эта задача является главной. Удобно сделать главной задачу, с кодом которой мы сейчас работаем. По умолчанию значение флага False.
isRealTime: флаг, показывающий работаем ли в реальном времени (атрибут t соответствует реальному времени). Этот режим обычно применяется при обмене данными с оборудованием (см. пример ex4), или если нужно посмотреть графику в реальном времени. По умолчанию значение флага False.
Как запустить моделирование¶
Каждую задачу нужно запустить в отдельном интерпретаторе Python. Это можно сделать как из системной консоли, так и используя, например, мою любимую IDE Spyder, где я стартую несколько консолей и в каждой из них запускаю нужны нужную мне задачу. При этом в консоли отображается состояние задачи.
После запуска главной задачи система начинает выполнять моделирование - отрабатывает машину состояний задач.
После того, как закончилось время моделирования, все задачи переходят в состояние Idle и ожидают дальнейших команд. Если при этом результаты моделирования нас не устраивают, мы можем перезапустить моделирование:
остановить нужные нам задачи и скорректировать их код и параметры.
заменить начальные условия в базе данных файла с диспетчером (они будут заданы автоматически заново при старте задач).
Графика¶
Двумерные графики (во времени)¶
Для отображения бегущего графика написан специальный объект Plot2D. Он будет рисовать фигуру, на которой расположены один или несколько графиков переменных от модельного времени.
При инициализации указывается объект и его атрибуты (переменные), которые будут отрисовываться на графиках фигуры. Затем, при каждом вызове метода Run графика, он добавит текущие значения атрибутов на графики, в текущий момент модельного времени. Фактически, объект графика каждый цикл накапливает во внутренних переменных указанные при начальной настройке данные. Отрисовка данных производится по вызову внутреннего метода Plot; он вызывается автоматически с заданным интервалом (0,5 сек) в реальном времени.
Пример создания объекта график внутри задачи, в методе Setup:
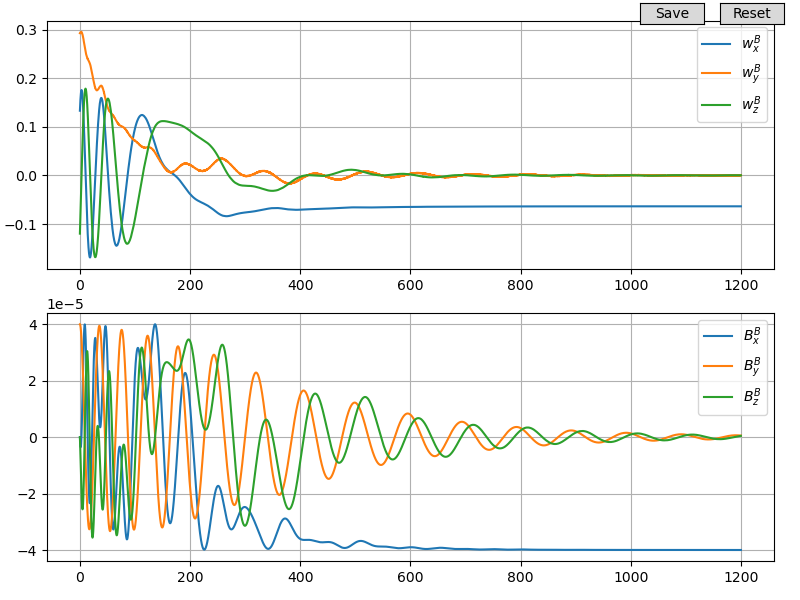
self.plot = Plot2D(DB=self)
self.plot.Setup('t', [['w_B'], ['B_B']])
В первой строке создаём экземпляр класса Plot2D, указывая что база данных (нужные поля) содержатся в объекте, в котором мы содержимся тоже, вместе с ней (self).
Во второй строке мы вызываем метод Setup, чтобы указать какие переменные будем брать для отрисовки. Метод имеет два обязательных параметра:
время. Указывается переменная (атрибут t), которая содержит текущее время.
список переменных для отрисовки.
Список переменных - это список из вложенных списков. На каждый элемент списка создаётся один график. Все графики будут расположены друг над другом.
Во вложенных списках мы указываем, какие переменные нужно рисовать на этих графиках. В нашем примере создаётся два графика, на верхнем отрисовываются компоненты вектора угловой скорости w_B, на втором компоненты вектора магнитного поля Земли B_B:
Можно на одном графике нарисовать несколько кривых. Для этого нужно указать их через запятую, как, например, вот в этом примере:
[['g'],
['g', 'x1']]
Здесь, на первом графике будет нарисована кривая сигнала управления g, а на втором будут две кривые: сигнал управления g и переменная состояния x1.
На поле фигуры мы видим кнопку для сохранения данных (в текущей версии она работает только при остановленной задаче). Накопленные за время моделирования данные сохраняются в контейнер pickle в рабочий каталог, имя файла содержит дату/время и имя фигуры.
График может добавлять точки как по одной, так и чанками (массивами или группами). В этом случае переменные должны являться массивами. При настройке необходимо указать размер этого массива в параметре chunkLen. При этом ожидается, что размер чанка не будет меняться в процессе моделирования.
Использование отрисовки чанками особенно удобно, когда требуется нарисовать переходной процесс в деталях. Например, есть регулятор, который выдаёт сигнал управления каждый интервал dt. Что же происходит между этими интервалами? Для этого в задаче, которая описывает непрерывную часть системы, необходимо получать решение для промежуточных микрошагов, которое можно точно также отправить на график. При этом мы будем видеть все выбросы, шильца и тому подобные интересующие нас особенности переходного процесса.
Иногда возникающая ошибка вида
Traceback (most recent call last):
- File ~/Science/ADCS/pySimSheduler/libGraph2D.py:270 in Run
self.Time.Add()
- File ~/Science/ADCS/pySimSheduler/libGraph2D.py:59 in Add
self.Data[self.i : self.i+self.Len] = getattr(self.Obj, self.attribute)
ValueError: could not broadcast input array from shape (2,) into shape (1,)
обычно имеет причиной либо неверное указание атрибута (обычно переменной времени), либо неверную размерность этого атрибута. Обычно это происходит, когда в задаче решение получено для вектора, а график настроен на поточечное отображение. Нужно, чтобы к моменту вызова метода Run графика все его переменные имели требуемую размерность.